优化 Distcc 集群的性能
接这篇:Distcc 快速上手与性能优化 - IHEXON 的主站
刚刚搭建起的 Distcc 编译 Kernel 6.1.0 大概加速了 30% ,显然这不太行,观察 Distcc 主节点的 CPU负载到了 100 %,其余5 个 ARM 节点的 CPU 负载均为 50% 左右,偶尔能跑满但很快就又开始摸鱼。
x86 节点的负载更低,属于是没干活。
一些用到的理论
四句话介绍 Distcc 逻辑
C++ 文件到 ELF 二进制文件中间几个过程:
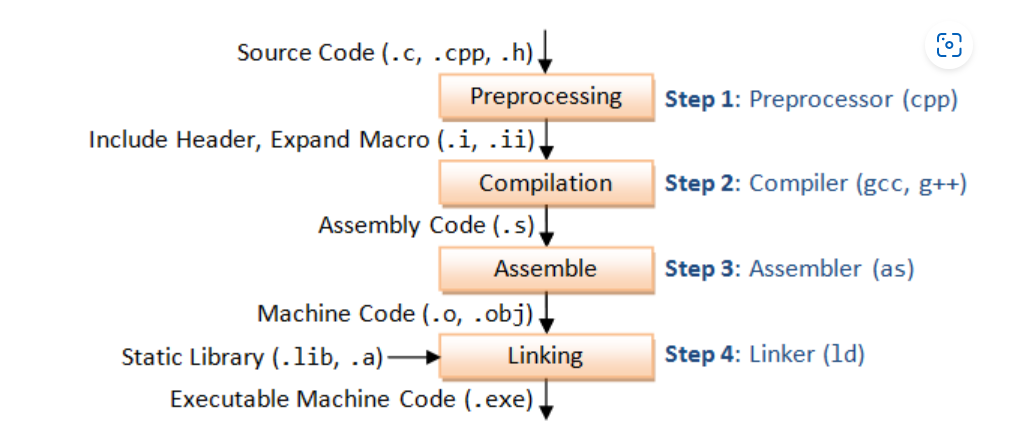
在 g++/gcc 生成汇编代码后,as 进行汇编翻译之前,distcc 会把生成的 .s 文件发送到 Distcc NodeX 进行汇编编译,然后 Distccd 回传 .o/.obj 给 Distcc 主编译机。主编译机接收 .o/.obj 进行二进制链接。
由于经过 gcc 预处理后的 .s 文件不依赖外部 Header,因为外部 Header 在 cpp 处理阶段已经被包含进来了,这就意味着 distcc 只需要分发这个 .s 文件到其他机器上就ok。
使用 make -jN 进行多线程构建时,make 会根据 Makefile 生成一张.c/.c++ 和.o/obj的依赖图,make 会根据这张依赖图进行源文件的多线程编译,所以 distcc 也不需要处理依赖关系。
Distccd 使用 sendfile 这个系统调用发布处理过的源文件,sendfile 提供一个文件描述符到另一个文件描述符直接的零拷贝,这比使用 read 和 write 要更快。
选择对的主编译机
主编译机负责 预处理和 分发汇编文件的编译负载到集群中,在分发编译失败的情况下,主编译机还要接受失败的编译载荷并尝试本地编译,所以主编译器的性能是集群中最好的。
主编译机预处理的速度越快,集群的工作越忙碌,不然其它机器就会摸鱼。
我把主编译机从 rk3399 平台移动到 rk3566 平台后,未作任何优化的情况下,编译 6.1.y 内核耗时缩短到 96 分钟。
原来的 编译环境在 rk3399 平台上,构建 6.1.y 源码树耗时 140 分钟。
我把主编译机从 rk3399 平台移动到 rk3566 平台后,未作任何优化的情况下,编译 6.1.y 内核耗时缩短到 96 分钟。
把主编译机移动到无头骑士 Dell 笔记本上,CPU为 Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz 上,耗时缩短到 63 分钟。
实际上 63 分钟已经很可观了,我在源码树内插入了 BPF 调试类的桩子,并且启用了几个 Debug 开关,导致编译器要处理许多的额外代码。去除这些不需要的 Debug 开关和代码桩。实际上 构建 6.1.y 源码树会更快。
优化 IO : 使用 zram 挂载到 /tmp 下
Distcc 的逻辑是本地预处理、集群编译。所以本地预处理的速度越快,distcc 就可以越快的把任务下发到集群内的各个机器。回顾我这里出现的状况:
刚刚搭建起的 Distcc 编译 Kernel 6.1.0 大概加速了 30% ,显然这不太行,观察 Distcc 主节点的 CPU负载到了 100 %,其余5 个 ARM 节点的 CPU 负载均为 50% 左右,偶尔能跑满但很快就又开始摸鱼。
显然是IO太慢,导致预处理太慢,Distccd 没有及时的将任务下发到集群里。
有 4 台 S905X3 机顶盒不痛不痒参与集群,这些机器配置 DDR3 4GB 内存,其中 2 个盒子拆开后发现内存颗粒被更换,为二次翻修盒子。
3 台盒子配置均相同,编号为# Distcc Node0/1/2, 这里参考# Distcc Node0 节点进行测试。
测使用 dd if=/dev/zero of=test bs=1M count=1024 status=progress conv=fsync 试连续写速度:
# Distcc Node1
$ dd if=/dev/zero of=test bs=1M count=1024 status=progress conv=fsync
1001390080 bytes (1.0 GB, 955 MiB) copied, 7 s, 143 MB/s
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 13.0264 s, 82.4 MB/s
使用 sudo hdparm -t /dev/mmcblk2 测试读取速度:
# Distcc Node1
$ sudo hdparm -t /dev/mmcblk2
/dev/mmcblk2:
Timing buffered disk reads: 688 MB in 3.01 seconds = 228.87 MB/sec
综合读写速度使用 dd if=/dev/mmcblk1 of=test bs=1M count=300 status=progress 测试:
$ dd if=/dev/mmcblk2 of=test bs=1M count=300 status=progress
313524224 bytes (314 MB, 299 MiB) copied, 4 s, 78.3 MB/s
300+0 records in
300+0 records out
314572800 bytes (315 MB, 300 MiB) copied, 7.03009 s, 44.7 MB/s
综合读写速度为 44.7 MB/s 。
但是# Distcc Node3插了假冒伪劣的闪迪 SDCARD 启动,这台EMMC被我弄坏了这里参考,写速度只有9.6 MB/s,读速度 109.26 MB/sec,综合读写速度只有 6.1 MB/s,我就不放数据了,恶心心,在集群这里是个这里是个瓶颈。
优化Distccd 在志愿机器的 IO 速度
但我不愿意掏钱买 sdcard 更不愿意等几天快递到货,考虑到盒子的 4GB DDR3 内存有点冗余,所以可以使用 zram 在内存里划分一块区域充当磁盘,我使用的 zram 配置工具是 ‣
配置文件在 /etc/systemd/zram-generator.conf
$ cat /etc/systemd/zram-generator.conf
[zram1]
mount-point = /mnt/zram1
compression-algorithm = lzo
fs-type = ext4
zram-size = 4096 * 3
compression-algorithm = lzo 使用 lzo对内存的数据进行压缩,当然,你也可以选择 zstd 提升 。
fs-type = ext4 内存盘使用 ext4 格式。
mount-point = /mnt/zram1 内存盘挂载点。
zram-size = 4096 * 3 分配 3 倍的内存空间给 zram 内存盘。
这里的配置完全是乱配的,也非常激进,因为后期我需要观察 zram 的压缩率来充分压榨内存空间。
配置完成后,使用 systemctl start zram1 启用 zram1 内存盘后,手动格式化成 ext4 挂载到 /mnt/zram1 下,我这里复制一份 构建好的 pcre-8.45/ 的源码树进 /mnt/zram1。 使用zramctl --output-all 观察 zram 的内存占用和压缩情况:
$ zramctl
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram1 lzo 12G 143.3M 39.1M 41.2M 6 /mnt/zram1
可以看到 DATA 有 143.3M ,COMPR 后为 39.1M这样算下来:

压缩率就取 3.5 吧
在盒子启动后,内存占用 差不多 300M 左右,Docker Engine 和Distcc 容器占用200 M左右,外加 1G 预留空间给用户程序,4G内存剩下 2500 左右的空间,这 2500M 物理内存全分给 ZRAM 内存盘,于是我们就有了 2500x3.5== 8960 M 的内存盘空间。
把 /etc/systemd/zram-generator.conf 文件中的 zram-size 修改成 8960 M 。
但注意,在编译过程中通常产生许多类型的文件,比如 o/obj,tar,bzip2,sqldata 等,实际上的源数据 / 压缩数据会小于3.5 / 1, 情况再恶劣一点,假如你的数据压缩率只有 2:1 或在这之下,那么 500M 文件就会把 zram 内存盘塞满,加上此时用户程序占掉 1024+M 内存,属于是把内存基本用完,极端情况下有爆内存的风险。有一句话比较好,在调试系统之前,你需要知道你在干什么。
在 Distcc 集群的志愿机中,设置环境变量 **TMPDIR=**/mnt/zram1 后启动 Distccd,所有接受的 .s 文件和汇编后的.o目标文件将输出到 /mnt/zram1 下,可以加速 gnu-as 对.s的编译速度和 Distccd 读取这些.o目标文件的速度。
优化 Distcc 在主编译器的 IO 速度
同样的套路,安装 ‣,编写配置文件:/etc/systemd/zram-generator.conf
主编译机在 Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz 的平台上,内存我给加到了 16 G,所以我这里就可以划分 13 G 的区域给 zram 内存盘,把整个 6.1.y 内核源码丢到 zram 内存盘里构建。
在内存 中划分 13 G 区域,使用压缩算法 lzo 压缩,于是得到一块差不多 40 G 的虚拟内存盘,完全可以Hold 住 6.1.y 内核树的构建过程, 剩下的空间你甚至可以找乐子把将 KVM 虚拟机移动到这个内存盘里启动….
优化网络
DIstcc 最好在千兆网络下,因为据我观察,在尽可能多分发任务的情况下,网卡负载通常在 15M/s-20M/s 左右,百兆交换机明显有瓶颈,千兆交换机完全满足需求。我这里是千兆交换机,考虑到小包传输速率也不会影响 Distcc 传输,因为分发下去的.s 汇编文件大小远超4k,所以 Nothings todo