重新编译内核真的是非常耗时,修改内核树内的驱动不用重新构建整个内核,但每修改调度,文件系统这块底层代码都需要重新构建一次 zImage 镜像,然后分发到测试机器上,构建 Kernel 巨浪费时间,不知道内核开发者这么受得了这种苦。
集群环境
集群处理器
4 台 Amlogic S905X3 的 TV BOX
1 台 RockPiN10 CPU 为 RK3399
1 台 Rock5B CPU 为 RK3588
S905X3 CPU 配置:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: ARM
Model name: Cortex-A55
Model: 0
Thread(s) per core: 1
Core(s) per cluster: 4
Socket(s): -
Cluster(s): 1
Stepping: r1p0
CPU max MHz: 2100.0000
CPU min MHz: 1000.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop asimddp
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec store bypass: Not affected
Spectre v1: Mitigation; __user pointer sanitization
Spectre v2: Not affected
Srbds: Not affected
Tsx async abort: Not affected
RK3399 CPU 配置:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 6
On-line CPU(s) list: 0-5
Vendor ID: ARM
Model name: Cortex-A53
Model: 4
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Stepping: r0p4
CPU(s) scaling MHz: 100%
CPU max MHz: 1416.0000
CPU min MHz: 408.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32
Model name: Cortex-A72
Model: 2
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
Stepping: r0p2
CPU(s) scaling MHz: 100%
CPU max MHz: 1800.0000
CPU min MHz: 408.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32
RK3588 CPU 配置:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: ARM
Model name: Cortex-A55
Model: 0
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Stepping: r2p0
CPU(s) scaling MHz: 100%
CPU max MHz: 1800.0000
CPU min MHz: 408.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop a
simddp
Model name: Cortex-A76
Model: 0
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 2
Stepping: r4p0
CPU(s) scaling MHz: 38%
CPU max MHz: 2400.0000
CPU min MHz: 408.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop a
simddp
Caches (sum of all):
L1d: 384 KiB (8 instances)
L1i: 384 KiB (8 instances)
L2: 2.5 MiB (8 instances)
L3: 3 MiB (1 instance)
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; __user pointer sanitization
Spectre v2: Not affected
Srbds: Not affected
Tsx async abort: Not affected
我使用 Docker 来标准化这6 台机器上的编译环境,编译器 GCC 和 G++ 版本统一为 version 10.2.1 20210110 (Debian 10.2.1-6)
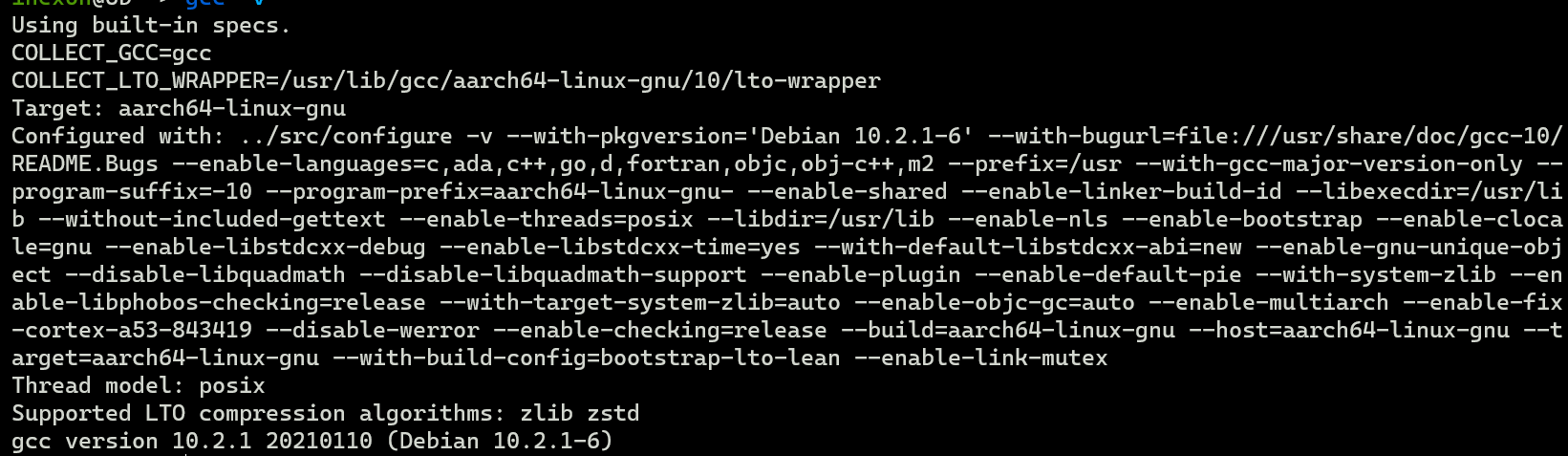
每个 Distcc 节点的系统环境
每个节点系统均为 Debian bullseye
单台 Distcc 节点的编译器为Debian bullseye软件源内的 gcc-10/g++-10 软件包,Hash 值:
ihexon@5b ~> sha1sum /usr/bin/aarch64-linux-gnu-gcc
785db25d6f89836f4c199c9a6d8bf4ecc6e42b15 /usr/bin/aarch64-linux-gnu-gcc
ihexon@5b ~> sha1sum /usr/bin/aarch64-linux-gnu-g++
cf867c744ce5938303a9b6f625f89fc5c79a696f /usr/bin/aarch64-linux-gnu-g++
存储环境
4 台 S905X3 的机顶盒的系统跑在 SDCARD 上,128 G 闪迪 A2 U3 存储卡。
可是这个 SDCARD 是假冒伪劣的,读写速度最高为 19.5 MB/s,我还是在淘宝闪迪旗舰店买的,太TM 扯了:
$ sudo dd if=/dev/zero of=/dev/mmcblk1 bs=4M count=64
64+0 records in
64+0 records out
268435456 bytes (268 MB, 256 MiB) copied, 13.7371 s, 19.5 MB/s
所以我配置了 zram ,并虚拟成一个 ext4 设备挂载到 /tmp 下,distccd 节点输出的临时文件都存储在 /tmp 的 zram 压缩内存盘里。
RockPi N10 的存储为 64GB 板载 EMMC,测试读写速度:
$ dd if=/dev/zero of=test bs=4M count=300 status=progress status=progress
1258291200 bytes (1.3 GB, 1.2 GiB) copied, 9 s, 140 MB/s
300+0 records in
300+0 records out
1258291200 bytes (1.3 GB, 1.2 GiB) copied, 9.01975 s, 140 MB/s
RockPi 5B 的系统也泡在 假冒伪劣的 闪迪 SDCARD 上,测试速度:
$ sudo dd if=/dev/zero of=/dev/mmcblk1 bs=4M count=64
64+0 records in
64+0 records out
268435456 bytes (268 MB, 256 MiB) copied, 13.7371 s, 19.5 MB/s
RockPi 5B 的 SDCARD 作为主编译机,这个 SDCARD 是主要性能障碍,这里说障碍的意思是,过慢的 IO 会极大拖慢构建大型项目的速递,这里的拖慢,意思是,使用 DISTCC 进行分布式编译 因为过慢的 IO 反而不如单台机器编译内核的速度。
最后做性能优化的时候会解决这个烦死人的问题。
网络环境
网段 192.168.1.0/24
6 台机器的网口均为千兆网卡。使用 6类网线与交换机连接。6 台机器的数据都通过 TP-LINK 千兆6 口交换机进行交换。这里没有性能瓶颈。
节点环境搭建:
配置 Distcc 节点的 Docker 环境
使用 Docker 统一每台机器的系统环境:
$ docker pull debian:bullseye # 拉取镜像
$ docker run --name compiler --network="host" -dit debian:bullseye bash # 后台运行镜像
$ docker exec -it compiler su - root
// Now we in debian bullseye container !
# apt update;
# 安装几个版本的编译器,按需选择
# apt install sudo gcc g++ make \
u-boot-tools flex bison \
cpio xz-utils libiberty-dev \
libgss-dev git clang llvm gdb \
lldb gcc-9 g++-9 g++-9-aarch64-linux-gnu \
gcc-9-aarch64-linux-gnu gcc-aarch64-linux-gnu \
gcc-aarch64-linux-gnu
由于某防火墙的存在,你可能需要换个快一点的更新源:
# echo '
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-backports main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-backports main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security bullseye-security main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian-security bullseye-security main contrib non-free
' | sed 's/https/http/g' > /etc/apt/sources.list
在 Debian:bullseye 容器里构建 Distcc 二进制文件:
$ git clone https://github.com/distcc/distcc --depth 1
$ sudo apt install autoconf automake libtool libkrb5-dev
$ cd distcc;
$ ./autogen.sh;
$ ./configure --prefix=/opt/distcc_bin --with-auth --without-avahi --disable-pump-mode
$ make -j8
$ make install
这里比较重要但又容易被遗忘的一点就是忘了执行 update-distcc-symlinks 生成编译器的软链接,没有这一步,distcc将无法调起本地编译器,在 debian:bullseye 容器内:
$ mkdir /opt/distcc_bin/lib/distcc -p
/opt/distcc_bin/sbin/update-distcc-symlinks
cc
c++
c89
c99
gcc
g++
c89-gcc
c99-gcc
x86_64-linux-gnu-gcc
x86_64-linux-gnu-g++
gcc-10
g++-10
x86_64-linux-gnu-gcc-10
x86_64-linux-gnu-g++-10
clang
clang++
clang-11
clang++-11
这一点比较奇怪,但可以理解,这就是 Unix 编程中的骚操作:drop-in replacement
update-distcc-symlinks 会在 /opt/distcc_bin/lib/distcc 下生成一组链接,这些链接都指向 distcc 可执行文件。
/opt/distcc_bin/lib/distcc# ls -alv
total 8
drwxr-xr-x 2 root root 4096 Jan 29 17:53 .
drwxr-xr-x 3 root root 4096 Jan 29 17:53 ..
lrwxrwxrwx 1 root root 16 Jan 29 17:53 c89 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 c89-gcc -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 c99 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 c99-gcc -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 cc -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 clang -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 clang++ -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 clang++-11 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 clang-11 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 c++ -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 gcc -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 gcc-10 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 g++ -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 g++-10 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 x86_64-linux-gnu-gcc -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 x86_64-linux-gnu-gcc-10 -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 x86_64-linux-gnu-g++ -> ../../bin/distcc
lrwxrwxrwx 1 root root 16 Jan 29 17:53 x86_64-linux-gnu-g++-10 -> ../../bin/distcc
创建软链并通过软链 /opt/distcc_bin/lib/distcc/g++ 执行并不等同于直接执行 distcc。这两种方式下distcc收到的argv[0]不同。当distcc检测到argv[0]是gcc或g++
时,有特殊逻辑来使得distcc的行为“看起来像”一个真实的GCC编译器。这也是实现“drop-in replacement”的基础。
Distcc 不推荐在 root 用户下运行,所以Debian 容器内添加一个叫 Ihexon 的普通用户:
$ docker exec -it compiler su - root
// Now we in debian bullseye container !
# adduser ihexon # add new user
# gpasswd -a ihexon sudo # add ihexon to sudo user group so that ihexon can use sudo
然后就可以导出这个配置好的 container,导入到其他机器上作为基础的 Docker image。
$ docker export compiler > compiler.tar
$ scp compiler.tar ihexon@192.168.1.X:/home/ihexon/ # 复制导出的镜像到其他机器的主目录下
// In other machine
$ docker import ./compiler.tar compiler
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
compiler latest 549371215c91 45 hours ago 1.84GB
到这里所有的 Distcc 节点环境都一致了。然后就可以通过 ssh 批量启动 Container 内的 Distccd。
# 在所有的机器上启动 debian:bullseye 容器内的 distccd
$ docker exec --user=ihexon -it compiler /opt/distcc_bin/bin/distccd \
--log-level notice --no-detach -p 6000 \
--allow 192.168.1.1/24 \
--listen 0.0.0.0 --log-stderr
测试
首先选择 6 台机器的一台机器做主节点,其余5台是志愿机,主节点分发编译荷载到志愿节点上,进而提构建大型项目的速度。就拿特别慢的 Node 来看看 Distcc 的加速效果。
所有的测试都在 Debian 容器内进行!
// 首先登录进主节点的 debian:bullseye 容器内
$ docker exec --user=ihexon -it compiler bash
// 拉取 node 的整个源码
$ git clone https://github.com/nodejs/node --depth 1
$ cd node
$ ./configure --prefix=/opt/node_bin_git
在使用 Distcc 之前需要设置一堆变量
- 将
update-distcc-symlinks生成的软链接路径,也就是编译器的 distcc 替身加入可执行文件加入到 PATH的头部。当使用which aarch64-linux-gnu-gcc-9,返回的是/opt/distcc_bin/lib/distcc/aarch64-linux-gnu-gcc-9而不是/usr/bin/aarch64-linux-gnu-gcc-9 - 设置
DISTCC_HOSTS环境变量,将志愿机器加入其中。我的志愿机分别是 fuckoff,fucktherules,fuckmyboss,fuckmylife,justfuck。主编译机为 whatanicedayha。
# 我嫌bash效率太低了,就切成了 Fish,用 set 设置环境变量,如果你是bash请自行更改
$ set -x PATH /opt/distcc_bin/lib/distcc $PATH
$ which aarch64-linux-gnu-gcc-9
/opt/distcc_bin/lib/distcc/aarch64-linux-gnu-gcc-9
$ set -x whatanicedayha 192.168.1.2
$ set -x fuckoff 192.168.1.100
$ set -x fucktherules 192.168.1.101
$ set -x fuckmyboss 192.168.1.102
$ set -x fuckme 192.168.1.103
$ set -x justfuck 192.168.1.104
$ set -x DISTCC_HOSTS "$NjQK:6000/8 $fuckoff:6000/8 $fucktherules:6000/4 $fuckmyboss:6000/4 $fuckme:6000/2 $justfuck:6000/4"
# 重要:设置编译器版本,这里我统一为 GCC-9/G++-9
$ set -x CC aarch64-linux-gnu-gcc-9
$ set -x CXX aarch64-linux-gnu-g++-9
在主编译机的 Debian 容器内运行 /opt/distcc_bin/bin/distccmon-text 1 查看主节点的荷载下发情况。然后再 node 源码目录下执行构建二进制文件动作:
$ ./configure --prefix=/opt/node_bin_git
$ make -j128
distccmon-text 1 会每隔一秒更新主机荷载下发志愿机的情况,就像这样:
771416 Compile crypto_x509.cc whatanicedayha[0]
770804 Compile node_metadata.cc whatanicedayha[1]
770756 Compile node_contextify.cc whatanicedayha[2]
770812 Compile node_os.cc fucktherules[0]
770799 Compile node_messaging.cc fucktherules[1]
771201 Compile crypto_rsa.cc fucktherules[2]
771456 Compile node_javascript.cc fucktherules[4]
770826 Compile node_process_events.cc fucktherules[5]
771287 Compile crypto_dh.cc fucktherules[7]
770841 Preprocess localhost[0]
770842 Preprocess localhost[3]
770825 Compile node_postmortem_metadata.cc fuckmyboss[0]
771028 Compile inspector_js_api.cc fuckmyboss[1]
770833 Compile node_process_object.cc fuckmyboss[2]
770806 Compile node_options.cc fuckmyboss[3]
770740 Compile node_builtins.cc justmylife[0]
770782 Compile node_http_parser.cc justmylife[1]
770669 Compile debug_utils.cc justmylife[3]
770717 Compile module_wrap.cc fuckoff[0]
770778 Compile node_file.cc fuckoff[1]
770789 Compile node_i18n.cc fuckoff[2]
770788 Compile node_http2.cc fuckoff[3]
770774 Compile node_external_reference.cc justfuck[0]
770647 Compile async_wrap.cc justfuck[1]
771435 Compile node_crypto.cc justfuck[2]
770674 Compile env.cc justfuck[3
志愿机的日志:
还记得再志愿机的Debian容器内运行 distccd 时候,我们加上了 --log-level notice 参数,这样志愿机会把实时接收到的编译荷载打印到终端内:
但你可能很快就发现一个问题就是,有些主机再摸鱼,摸鱼的意思就是,一台或多台志愿机老半天才接受收到主节点下发的荷载,CPU根本就没活可干。
你还可能发现Distcc 集群根本就没起到多少加速左右,甚至不如单台机器本地编译快。
显然,这需要点优化,然而优化是个大坑,准备好和入坑了吗?
性能优化
有趣的地方从这里才开始呢:)
但再写下去就要猝死了,有空写….